
Discrimination against a group of people or against individuals can be conceptualized in a number of different ways. These include disparate treatment, disparate impact, proxy discrimination, differential prediction, differential validity, and differential performance. Here, we will focus on differential performance. This is measured as the difference or ratio of one group’s model quality measurement to that of another group. For example, we might look at relative AUC scores for an employment hiring model, comparing the AUC for Black applicants to that of white applicants. If the AUC for Black applicants is substantially lower than that for white applicants, then there is evidence that the model has differential performance. It is then assumed that the model must be discriminatory because it is less effective for Black applicants than whites.
In this notebook, we create a simple example that proves that differential performance measures can be misleading. Instead of just being the result of a bad model, differential performance may arise naturally due to differences in the distribution of input data from one group to another — differences that may not be discriminatory or may be outside the control of the modeler or company performing the modeling.
Below, we create a synthetic dataset with a few simple variables meant to mimic an employment hiring process. The idea is that we are a company that wants to identify and hire “highly productive” employees. To do this, we use this dataset to create a model that uses work experience and an additional factor to predict whether an employee will be highly productive. The company would use the model by scoring prospective employees and hiring those with the highest scores.
This synthetic dataset and model show that a well-built model can still show evidence of differential performance. In particular, evidence of differential performance occurs when an input variable has a lower variance for one group relative to another, even when the model accurately captures the true data-generating process for all groups. This is important because it means that differential performance as a measure of model-based discrimination can be misleading. There may be non-model-related — and possibly non-discriminatory — reasons why a model should show differential performance. The converse is also true: a bad model that does not show evidence of differential performance may still be a discriminatory model. Therefore, only looking at a measure of differential performance is not sufficient to identify discrimination. Instead, we should be concerned with (1) ensuring that the model accurately captures the data-generating process, (2) determining whether that data-generating process is itself discriminatory, and (3) determining whether the usage of the model is discriminatory.
We first start by creating the synthetic dataset that will be used for the model and differential performance assessment. The advantage of using this synthetic dataset is that we know exactly what the data-generating process is, which means we can make a model that perfectly replicates that process. In other words, we will know that the model that we will build will be the best model possible.
Before proceeding, we will define the data-generating process as the process that causes the data to occur as they do. Here, the synthetic data are created (or “generated”) using chosen distributions and parameters. As such, we know what the inputs will be, and we also know how the inputs work to create the output (i.e., how the variables work together to form the Highly Productive outcome). We will also know exactly how uncertainty comes into the process.
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
np.random.seed(31415)The dataset we create has three influential factors. The first is the employee’s Experience, which might be the time spent working on the job, tenure, or some other measure of experience. The second variable is a vaguely defined Other Factor that is important for determining productivity. This might be something like specialized training, education, or something else. What the factor represents is not important for this hypothetical example — we include it because we want multiple variables in the model. These two variables represent all the measurable information that the company has that can be used to predict whether a person is highly productive. Of course, there are other unmeasurable factors. These are captured in the Unmeasurable Factors variable which corresponds to the noise or uncertainty of the process. Importantly, these unmeasurable factors are independent of both race and measurable factors.
We also create Minority and Majority variables. These are created to be entirely unrelated to the other variables in the model, except that we change the variance of the Experience variable for minorities in the next step.
data = np.random.randn(250000, 2)
data = pd.DataFrame(data=data, columns=['Experience', 'Other Factor'])
data['Unmeasurable Factors'] = np.random.logistic(0, 1, len(data))
data['Minority'] = np.random.choice([0, 1], len(data))
data['Majority'] = 1 - data['Minority']The step below is the key to generating differential performance in an otherwise accurate and potentially non-discriminatory model. For minorities, we reduce the variation in the Experience variable by one-half. Importantly, this does not change the average level of experience for minorities. The effect is that there are fewer minorities with very little experience, but there are also fewer minorities with large amounts of experience. Whether this change represents a non-discriminatory impact is questionable, but it is certainly outside the control of the modeler.
For both groups, we add 10 to the Experience variable, making the average experience equal to 10 years. This makes the variable appear more realistic but does not impact results.
data.loc[data['Minority'] == 1, 'Experience'] = \
data.loc[data['Minority'] == 1, 'Experience'] * 0.5
data['Experience'] = data['Experience'] + 10We now complete the data-generating process by creating the outcome, Highly Productive. A person is highly productive if the sum of their Experience, Other Factor, Unmeasurable Factor, and a constant, -10, is above zero. It is important to emphasize that this is the data-generating process — in other words, it is the ground truth. We are to assume that in the real world, applicants labeled as being highly productive are actually highly productive.
input_vars = ['Experience', 'Other Factor', 'Unmeasurable Factors']
data['Highly Productive'] = -10 + data[input_vars].sum(axis=1)
data['Highly Productive'] = data['Highly Productive'] > 0Here, we print a few records from the dataset to show what they look like.
Next, we show the average values for all the variables in the dataset. Importantly, there is no meaningful difference in the rate of minorities and non-minorities that are defined as being highly productive: both groups are, in truth, approximately 50% likely to be highly productive.
(data
.drop(columns=['Majority'])
.groupby('Minority')
.mean()
.T
.reset_index()
.rename(columns={'index': 'Variable', 0:'Majority', 1:'Minority'})
.style
.format(precision=3)
.hide(axis='index'))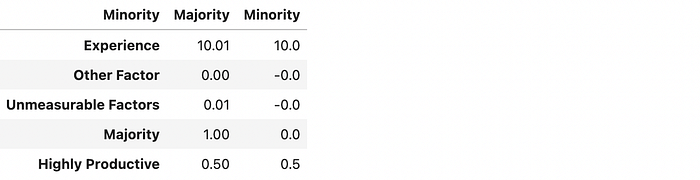
Below, we show the standard deviations of the variables. As expected, the only meaningful difference is in the Experience variable. As designed, the standard deviation of Experience for minorities is about half of that for the majority group.
(data
.drop(columns=['Majority'])
.groupby('Minority')
.std()
.T
.reset_index()
.rename(columns={'index': 'Variable', 0:'Majority', 1:'Minority'})
.style
.format(precision=3)
.hide(axis='index'))
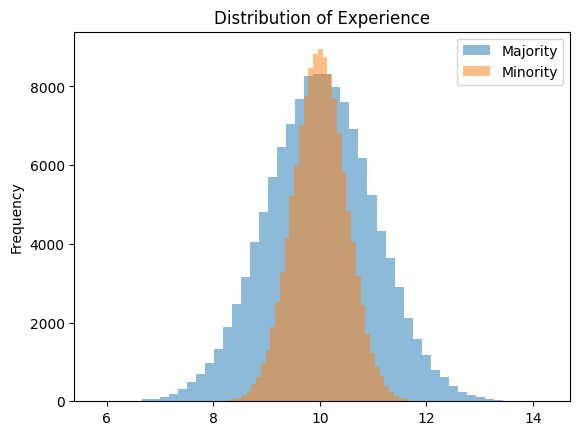
That the averages are the same, but the standard deviations are different is shown graphically below. We see that the majority group has a much wider distribution of “Experience” than the minority group, but they are both centered around ten years of experience.
(data.replace({'Minority': {0: 'Majority', 1: 'Minority'}})
.groupby('Minority')['Experience']
.plot.hist(
title="Distribution of Experience",
bins=100,
alpha=0.4,
legend=True,
figsize=(8, 6)
))
At this point, we assume that the company’s data scientist has been tasked with building a model to predict productivity. After working with the data, they use a logistic regression and the two factors we created above. This would be the right thing to do because the logistic regression accurately captures the data-generating process created above with all the information available. In other words, the logistic regression is the best possible model for both minorities and non-minorities. Any other model, including any machine learning models or even a deep neural network, would only approximate the fit of this logistic model.
After running the logistic regression, we print some summary output. Note the values of the coefficients at the bottom. We see that the const term is close to negative ten, while the Experience and Other Factor variables’ coefficients are close to one. This means the model accurately captures the data-generating process for both minorities and non-minorities.
import statsmodels.api as sm
model = sm.Logit(
data['Highly Productive'],
sm.add_constant(data[['Experience', 'Other Factor']])
).fit()
model.summary()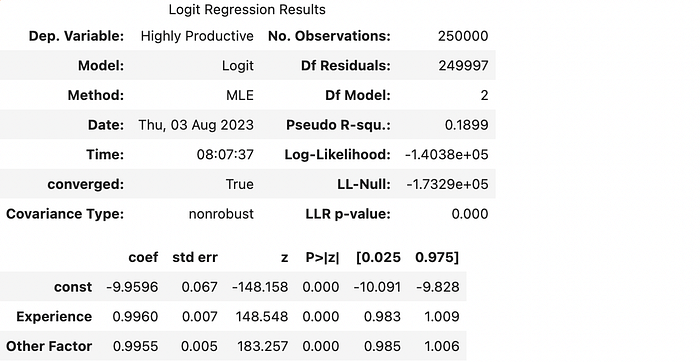
In the step below, we calculate predictions with the model, which will be used to calculate differential validity.
data['Predictions'] = model.predict(
sm.add_constant(data[['Experience', 'Other Factor']])
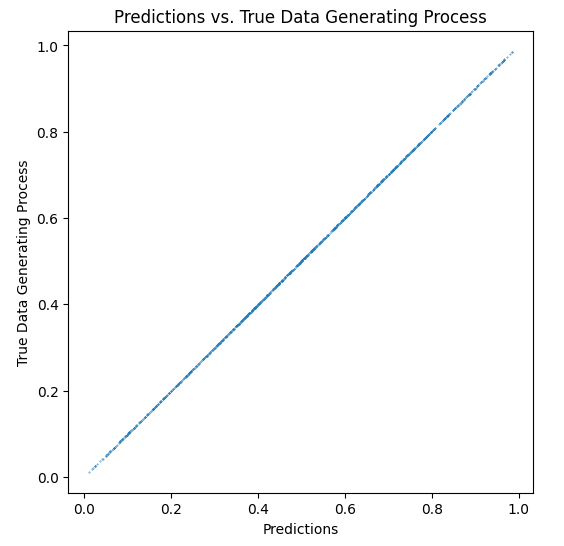
)The graph below further shows that the logistic regression has accurately estimated the true data-generating process. This can be seen by the fact that the logistic regression’s predictions nearly perfectly align with the true data-generating process values along a 45-degree line. While the technical aspects of this are beyond the scope of this notebook, one can say that the model would be flawed if the predictions did not fall along the 45-degree line. Seeing that they do indicates that the model is the best possible model for everyone scored by it (i.e., it is the best possible model for minorities and non-minorities).
data['True Data Generating Process'] = \
-10 + data['Experience'] + data['Other Factor']
data['True Data Generating Process'] = \
1 / (1 + np.exp(-data['True Data Generating Process']))
data.sample(n=1000).plot.scatter(
x='Predictions',
y='True Data Generating Process',
title='Predictions vs. True Data Generating Process',
s=0.1,
figsize=(6, 6),
)
Here, we use SolasAI’s custom_disparity_metric to calculate the ROC-AUC scores for minorities and majority group members. We find that, despite the model being the best possible model for both minorities and non-minorities, we see evidence of differential performance. The AUC for the minority group is about 0.76, while it is about 0.80 for the majority group. This difference, about 5.1%, would likely cause concern in a differential performance analysis.
import solas_disparity as sd
from sklearn.metrics import roc_auc_score
relative_auc = sd.custom_disparity_metric(
group_data=data,
protected_groups=['Minority'],
reference_groups=['Majority'],
group_categories=['Race'],
metric=roc_auc_score,
outcome=data['Predictions'],
label=data['Highly Productive'],
difference_threshold=lambda difference: difference > 0,
ratio_threshold=lambda ratio: ratio < 0.95,
)
print_vars = ['Total', 'ROC AUC SCORE', 'Difference', 'Ratio', 'Practically Significant']
sd.ui.show(relative_auc.summary_table[print_vars])
People generally assume that a model that shows that a given quality metric is worse for one group means that the model itself is a driver of discrimination. While this can be true, as we have shown, it is not always correct. In this example, we show that the distribution of the data that goes into the model can drive differential performance — even when the model being used is the best possible model for all groups. This means that measurements of differential performance must be taken with a grain of salt.
While we have shown that differential performance is not always a reliable measure of model-based discrimination, we have not shown that using this data in this model is not discriminatory in other ways. In other words, we still should ask, “Is this model discriminatory given that it uses data with unequal variances by group?” The answer is — maybe. The use of data such as these can drive there to be disparate impact discrimination when the model is used to select employees. In the next notebook in this series, we will show when this model might lead to discriminatory outcomes and discuss what can be done to mitigate the discrimination.
If you liked this article, you might like my forthcoming book, co-authored with Ali El-Sharif and Serg Masis, Building Responsible AI with Python. Please take a look and consider pre-ordering it. Also, if you’re interested in testing your models for evidence of disparities, as we did above, please consider trying SolasAI’s publicly-available disparity testing library, solas-disparity.